
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ERD
- 부스트코스
- 모두를 위한 컴퓨터 과학
- Java Programming
- 관계형 데이터베이스
- CS50
- 기초프로그래밍
- til
- exception
- CS기초지식
- 알고리즘
- 이진법
- Compute Science
- SW
- CS 기초
- CS 기초지식
- Computer Science
- edwith
- WebProgramming
- 면접을 위한 CS 전공지식 노트
- 객체지향
- 데이터베이스 모델링
- SSAFY 9기
- 삼성청년SW아카데미
- 예외처리
- w3schools
- ssafy
- 모두를 위한 컴퓨터 과학(CS50)
- java
- 상속
- Today
- Total
Joslynn의 하루
MSA Full-Stack 개발자 양성 과정 -26일차 노트 필기_데이터베이스(Oracle)_데이터베이스 모델링_220826 본문
MSA Full-Stack 개발자 양성 과정 -26일차 노트 필기_데이터베이스(Oracle)_데이터베이스 모델링_220826
Joslynn 2022. 8. 28. 17:40데이터베이스란?
: 데이터를 저장하는 공간(→ 관계형데이터베이스 이론에 맞추어 저장)
관계형데이터베이스란?
: 테이블과 테이블 간 연관관계(pk와 fk)를 설정해서 테이블들을 수평관계로 데이터를 저장하는 것.
데이터베이스를 구축하는 목적은?
: 데이터의 양이 급증하면서, 데이터의 중복과 정합성 문제, 성능저하 이슈가 있다.
데이터베이스 이론에 맞추어 데이터베이스를 구축함으로써 중복된 데이터를 최소화하고,
일관성, 데이터 정확성 보장, 무결성을 유지하고자 함이다.
데이터베이스 모델링
1) 개념적 설계
: 업무를 일반화한다. - 고객과의 인터뷰를 통해 니즈를 파악하여 작성된 시나리오를 바탕으로 업무를 일반화한다.
- Entity 추출

- Attribute 추출

- Relationship 추출 (Entity와 Entity 사이의 관계)

- Identifier 추출
** Identifier: 하나의 실체 내에서 각각의 인스턴스를 유일 (Unique)하게 구분해 낼 수 있는 속성 또는 속성 그룹
1.후보 식별자 (Candidate Identifier)
: 실체 내 각 인스턴스를 유일하게 구분 할 수 있는 속성, 기본키의 후보속성
2.주 식별자 (Primary Identifier)
: 실체에서 각 인스턴스를 유일하게 식별하는 데 가장 적합한 키, 해당 실체를 대표
3.대체 식별자 (Alternate Identifier)
: 후보키 중에서 기본키로 선정되지 않은 속성
4.복합 식별자 (Composite Identifier)
: 하나의 속성으로 기본키가 될 수 없을 때, 둘 이상의 컬럼을 식별자로 정의
5.대리 식별자 (Surrogate Identifier)
: 인위적으로 추가한 식별자 (식별자가 너무 길거나 여러 개의 속성일 경우)
6.외래 식별자 (Foreign Identifier)
: 부모 엔티티의 기본키를 자식 엔티티 에서 참조
- 차수성(1:1, 1:다, 다:다)
1) 일대일

2) 일대다
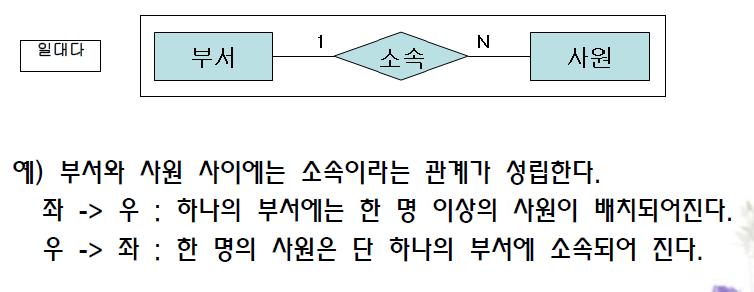
3) 다대다

- 선택성 (반드시 - must, 있을지도- may)

* 위의 6단계를 진행하면 최종 산출물 ERD를 만든다.
* 개념적 설계 단계에서 나온 ERD를 바탕으로 논리, 물리적 설계를 진행
* 개념적 설계 단계에서는 관계형 데이터베이스 이론을 적용하지 않는다.
2) 논리적 설계
: 관계형데이터베이스 이론을 적용하여 설계한다.
: 어떤 데이터베이스를 사용할지는 고려하지 않는다.

- 매핑룰을 적용한다
Entity → Table(Schema)
Attribute → 컬럼명
Identifier → pk와 fk

- Relationship(관계)를 해소한다.
- 식별관계: 한쪽의 pk를 다른쪽의 pk로 전이(pk이면서 fk) 1 : 1
- 비식별관계: 한쪽의 pk가 다른 쪽의 일반속성으로 전이 1 : 다
* 1 : 1인 경우: 어느쪽의 테이블이든 한쪽의 pk를 다른 쪽으로 전이한다.
* 1 : 다인 경우: 1쪽의 pk를 다쪽의 일반 속성으로 전이한다.
* 다 : 다인 경우: 새로운 Entity(table)을 만들고, 양쪽의 pk를 새로운 Entity로 전이(복합키)
- 정규화 과정 진행
: 데이터 중복 최소화
: 정규화를 많이 하면 테이블이 더 작은 단위로 분리
: 속성간의 함수종속성에 의해 발생하는 이상현상을 제거


정규화 과정)
* 1차 정규화: 반복되는 속성이나 null을 많이 허용하는 속성은 별도의 Entity로 만들고, 1 : 다인 관계로 해결한다.
* 2차 정규화: 복합키가 있을 때, 일반속성들이 모두 복합키에 의존적이어야 한다.
만약, 일반속성이 복합티의 일부분에만 의족적이라면 속성을 제거한다.
* 3차 정규화: 일반 속성들이 모두 기본키(pk)에 의존적이어야 한다.
만약, 일반속성이 일반속성에 의존적이라면 제거한다.

3) 물리적 설계
: 관계형데이터베이스 이론을 적용하고, 어떤 DBMS를 사용할지를 선택한 상태에서 설계한다.
: 논리적 설계 단계에서 나온 내용(schema 정보)을 바탕으로 create table, index, sequence, view 등등을 실제 물리적 공간에 생성한다. - 이 때, DBMS에 해당하는 데이터타입을 결정한다.(자료형과 사이즈)
: 샘플데이터를 추가하여 기능을 test하면서, 성능 저하의 이슈가 있는지 체크
- 만약, 성능 이슈가 생긴다면, 필요에 의해 역정규화를 할 수도 있음

**역정규화
: 시스템의 성능향상을 위해서 긍정적으로 도움이 될 수 있는 요인이 된다면 역정규화의 유형이 된다.
: 정규화를 해놓고 데이터 사용량을 분석한 다음에 성능향상을 위해 역정규화를 한다 .

역정규화 유형)
1. 데이터 중복 컬럼
: 조인을 통해 다른 테이블에 있는 컬럼의 데이터를 조회하는 경우 아예 해당 컬럼을 중복함으로써 조회 시 조인 수행X

2. 파생 컬럼의 생성
: 계산을 통해서 얻어질 수 있는 결과 값을 테이블의 컬럼으로 만들어서 저장하여 조회의 성능을 향상
3. 테이블 분리

1) 레코드 분리

2) 컬럼 분리


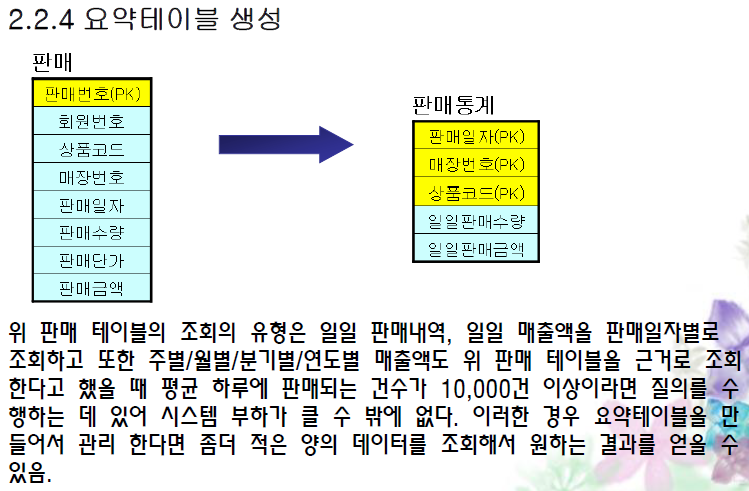
3. 요약테이블 생성
: Group By 와 Sum 등을 이용하여 가공된 결과를 얻는 질의를 자주 실행하게 되는 경우 조회의 프로세스를
줄이기 위해 요약된 정보만을 저장하는 테이블을 만든 것
4. 테이블 통합
: 조회 성능 향상을 위해 분할되었던 테이블을 다시 합치는 것

** 추가 내용 참고자료
[Oracle] PL/SQL
공부했던 자료 정리하는 용도입니다. 재배포, 수정하지 마세요. 예제는 Oracle Database에서 기본으로 제공되는 SCOTT계정 데이터로 진행됩니다. SQLDeveloper에서 PL/SQL 실행하기 보기 → DBMS 출력 → DBM
pridiot.tistory.com



